AWS SAA 준비 - (2) 성능이 뛰어난 아키텍처 설계
AWS에서 제공하는 SAA 준비 교육 영상 컨텐츠를 글로 적었습니다.
1. 성능이 뛰어난 아키텍처 설계
1.1 성능이 뛰어난 스토리지 및 데이터베이스 선택
1.2 캐싱을 적용하여 성능 개선
1.3 탄력성과 확장성을 갖춘 솔루션 설계
1.4 솔루션에서 운영 우수성을 지원할 수 있는 설계 기능 선택
EBS 블록 스토리지
- EBS는 블록 스토리지에 해당한다. EC2 인스턴스에 EBS 볼륨을 디스크로 탑재할 수 있다.
- EBS 볼륨은 성능 면에서 일장일단이 있다. SSD는 더 비싸고 IOPS, 즉 랜덤 엑세스와 읽기 및 쓰기 성능이 더 좋다. HDD는 저렴하고 순차적 읽기 및 쓰기 성능이 더 좋다. 순차적 빅데이터 파일 처리를 예로 들 수 있다.
| 솔리드 스테이트 드라이브(SSD ) | 하드 디스크 드라이브(HDD) | |||
|---|---|---|---|---|
| 범용 | 프로비저닝된 IOPS | 처리량 최적화 | 콜드 | |
| 최대 볼륨 크기 | 16TiB | 16TiB | 16TiB | 16TiB |
| 볼륨당 최대 IOPS | 10,000 | 32,000 | 500 | 250 |
| 최대 처리량/볼륨 | 160MiB/s | 500MiB/s | 500MiB/s | 250MiB/s |
- 아이옵스(Input/Output Operations Per Second, IOPS)는 HDD, SSD, SAN 같은 컴퓨터 저장 장치를 벤치마크하는 데 사용되는 성능 측정 단위다. IOPS는 보통 인텔에서 제공하는 Iometer 같은 벤치마크 프로그램으로 측정된다. (위키피디아 정의)
- 큰 범주 안에서는 프로비저닝된 IOPS의 성능이 더 좋지만 SSD 옵션으로는 더 비싸다. HDD 쪽에서는 처리량 최적화 HDD가 성능이 더 좋고 처리량이 더 많으며 더 비싼 HDD 옵션이다.
- 먼저 내려야 할 결정은 SSD를 선택할지 HDD를 선택할지이다. 그런 다음 이 큰 범주 안에 실제 성능을 결정하는 두 번째 선택이 있다.
- 고성능 아키텍처의 또 다른 관건은 모든 정적 콘텐츠를 서버에 유지하는 대신 S3에 오프로드하는 것이다. HTML 파일, JS 파일, CSS 파일, 이미지, 비디오 등의 정적 콘턴츠가 있는 정적 폴더를 웹 서버에 두는 대신 S3로 이동하는 것이다. 그러면 웹 서버의 성능이 크게 향상되고 웹 서버의 부하를 덜어 준다. 이렇게 확보된 CPU와 메모리를 모두 동적 콘텐츠 제공에 사용할 수 있다.
파일을 S3에 업로드하려면 어떻게 해야 할까?

- 먼저 리전 중 하나에 버킷을 생성한다.
- 버킷 이름은 S3 URL의 하위 도메인이 된다. 그런 다음 이 버킷에 원하는 수의 객체를 업로드할 수 있다. S3 객체는 버킷 이름에 따라 자동으로 URL이 할당된다.
- URL은 가상 호스팅 스타일 또는 경로 스타일이 될 수 있다. 가상 호스팅 스타일 URL에는 도메인 이름의 일부로 버킷이 포함되며 경로 스타일 URL에는 경로의 첫 번째 부분에 버킷이 있다. URL의 리전을 지정하거나 리전이 없는 URL도 사용할 수 있는데 이 경우 버킷이 저장될 적절한 리전으로 연결된다.
- 핵심은 리전과 독립적인 이름을 참조할 수 있더라도 버킷은 항상 리전에 연결된다는 것이다.
- 또 버킷 이름은 전역적으로 고유하다. ‘my bucket’이라는 버킷이 있다면 모든 리전의 다른 어떤 버킷도 이 이름을 사용할 수 없다.
- 버킷 이름 뒤의 파일 전체 경로를 ‘키’라고 한다.
버킷의 요금
- 사용한 만큼만 비용을 지불
- 월별 GB
- 리전 밖으로 전송
- PUT, COPY, POST, LIST, GET 요청
- 무료
- Amazon S3로 전송
- Amazon S3에서 같은 리전의 Amazon CloudFront로 전송
S3에는 여러 스토리지 클래스가 있다.
가장 중요한 클래스는 S3 Standard와 S3 Standard - Infrequent Access 이다. 이 두 클래스는 일장일단이 있다.
- 범용: Amazon S3 Standard
- 가용성 요구 사항이 더 높은 경우: 교차 리전 복제를 사용한다.
- 엑세스 빈도가 낮은 데이터: Amazon S3 Standard - Infrequent Access
- 저장된 GB당 비용이 저렴
- PUT, COPY, POST 또는 GET 요청당 비용이 높음
- 최소 30일 스토리지
S3 Standard - Infrequent Access는 스토리지 요금이 저렴하지만 검색 요금이 약간 비싸며 S3 Standard는 검색 요금이 저렴한 대신 스토리지 요금이 약간 비싸다.
S3 Standard - Infrequent Access에는 30일의 최소 스토리지 기간도 있다.
데이터 파일을 읽는 일반적인 패턴은 데이터 처리에 관심이 많은 초기에는 자주 엑세스하지만 시간이 지남에 따라 엑세스가 뜸해지고 결국 거의 엑세스하지 않게 되지만 그래도 일정 기간 동안 보유해야 한다. 이 경우 S3 수명 주기 정책이 유용하다.
S3 수명 주기 정책은 시간 경과에 따라 S3 Standard에서 S3 Standard - Infrequent Access로 다시 Glacier로 데이터를 자동으로 이동할 수 있다. 마침내 더 이상 필요하지 않게 되면 파일을 삭제할 수 있다.
Amazon S3 Standard » S3 Standard - Infrequent Access » Amazon Glacier » 삭제
수명 주기 정책을 사용하면 오래된 콜드 데이터는 보다 저렴한 스토리지로 이동하고 당장 관심이 있는 핫 데이터는 엑세스 빈도가 높은 스토리지에 남겨 둘 수 있다.
예시문항 1
Amazon S3 객체 스토리지가 블록 및 파일 스토리지와 다른 점은 무엇입니까? (3개 선택)
A. Amazon S3는 객체를 무한대로 저장하는 것이 가능
B. 객체가 불변임(바이트 하나라도 바꾸려면 객체를 교체해야 함)
C. 객체가 가용 영역 간에 복제됨
D. 객체가 모든 리전에서 복제됨
해설
단일 리전 내의 가용 영역 간에 객체가 복제되지만 모든 리전에서 복제되는 것은 아니다.
S3는 리전으로 범위가 지정된 서비스이다.
정답은 A, B, C 이다.
예시문항 2
다음 중 Amazon EBS의 기능에 대한 설명은 무엇입니까? (2개 선택)
A. Amazon EBS에 저장된 데이터는 가용 영역 내에 자동 복제됩니다.
B. Amazon EBS 데이터는 테이프에 자동 백업됩니다.
C. Amazon EBS 볼륨은 암호화가 가능합니다.
D. 연결된 인스턴스가 중지되면 Amazon EBS 볼륨의 데이터가 손실됩니다.
해설
B를 제거할 수 있다. 데이터는 자동으로 백업되지 않고 테이프에 백업되지도 않는다.
D도 제거할 수 있다. EBS의 강점은 인스턴스가 중지되어도 데이터가 손실되지 않는다는 점이다.
이것은 인스턴스 스토어의 한계이며 인스턴스 스토어 대신 EBS를 사용하는 이유다.
정답은 A, C 이다.
2. 데이터베이스의 고성능 스토리지
AWS에는 몇 가지 데이터베이스 옵션이 있다.
- Amazon Relational 데이터베이스 서비스
- Amazon DynamoDB
- Amazon Redshift
RDS, 즉 Relational Database Service를 사용하여 관계형 데이터베이스를 설정할 수도 있고 Amazon DynamoDB로 관리형 NoSQL 데이터베이스를 설정할 수도 있다.
Amazon Redshift로 데이터 웨어하우스를 설정할 수도 있다. Redshift는 순차적 인터페이스를 제공하며 분석 쿼리와 트랜잭션 쿼리가 있는 경우에 유용하다. 행을 삽입하거나 가져오지 않고 전체 테이블에서 집계 수를 계산할 수 있다. 예를 들어 전국 각 매장의 판매량 수치를 알고 싶다면 Redshift를 사용하면 된다. Redshift는 이런 종류의 쿼리에 답하도록 설계되었다.
그렇다면 언제 RDS를 사용해야 하고 언제 사용하면 안될까?
RDS는 관리되는 관계형 데이터베이스를 제공한다.
Amazon RDS가 적합한 사례
- Amazon RDS를 사용
- 복잡한 트랜잭션 또는 복잡한 쿼리
- 중간 또는 높은 수준의 쿼리/쓰기 속도
- 단일 작업자 노드/샤드를 사용
- 높은 내구성
- Amazon RDS를 사용하지 않음
- 대규모 읽기/쓰기 속도(예: 150,000 쓰기/초)
- 샤딩
- 간단한 GET/PUT 요청 및 쿼리
- RDBMS 사용자 지정
RDS는 MySQL, Postgres, MariaDB, Auroa SQL Server, Oracle 중에서 선택할 수 있다.
조인 또는 기타 복잡한 쿼리나 트랜잭션을 수행하는 경우에는 RDS를 사용하는 것이 좋다.
쿼리 쓰기 속도는 DynamoDB보다 낮다. 아주 높은 읽기-쓰기 속도나 처리량이 필요하면 DynamoDB를 고려하자.
조정 및 자동 샤딩이 필요한 경우에도 DynamoDB가 좋은 옵션이다.
DynamoDB는 자동으로 데이터를 샤딩하여 여러 서버에 분할할 수 있다. 이 때문에 조정이 아주 잘 된다.
DynamoDB는 서버를 더 추가하여 수평적으로 확장할 수 있기 때문에 무제한의 스토리지를 제공한다.
RDS는 데이터의 내구성이 뛰어나서 장애가 발생해도 데이터가 손실되지 않는다.
이런 내구성은 RDS와 DynamoDB에서 얻을 수 있다.
엑세스 패턴이 간단한 GET과 PUT으로 구성된 경우에도 DynamoDB가 좋은 옵션이다.
RDS를 사용하지 말아야 할 또 다른 경우는 RDS가 제공하지 않는 특정 버전의 관계형 데이터베이스가 필요하거나 데이터베이스를 사용자 지정하려는 경우이다.
RDS를 조정하는 다른 방법은 읽기 전용 복제본을 사용하는 것이다.
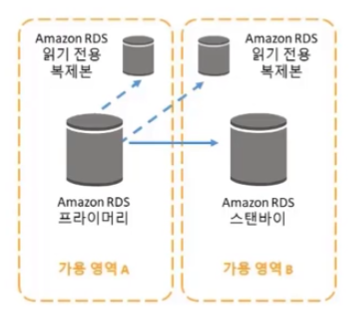
읽기 전용 복제본은 Aurora, Postgres, MySQL, MariaDB에서 지원된다.
읽기 전용 복제본을 사용하면 읽기 요청을 읽기 전용 복제본에 오프로드하고 프라이머리 데이터베이스의 부하 일부를 덜 수 있다.
DynamoDB: 프로비저닝된 처리량
처리 용량 요구 사항에 따라 리소스 할당 (읽기/쓰기)
- 읽기 용량 단위(최대 4KB 크기의 항목)
- 초당 1건의 강력한 일관된 읽기
- 초당 2건의 최종적 일관된 읽기
- 쓰기 용량 단위(최대 1KB 크기의 항목)
- 초당 1건의 쓰기
DynamoDB는 영구 데이터 스토어로 쉽게 설정하고 사용할 수 있는 AWS의 관리형 NoSQL 옵션이다.
엑세스 패턴이 DynamoDB가 지원하는 주요 가치 패러다임과 일치한다면 DynamoDB는 RDS의 좋은 대안이다.
DynamoDB 테이블을 생성할 때 필요한 공간을 지정하지 않아도 데이터 공간이 바뀌면 DynamoDB 테이블이 늘어난다.
원하는 초당 읽기-쓰기 횟수, 즉 처리량을 지정하면 DynamoDB는 이 처리량을 처리하기 위해 테이블을 조정한다.
처리량은 RCU와 WCU로 지정된다.
RCU, 즉 읽기 용량 단위란 최대 4KB 크기 항목의 초당 읽기 1회를 말한다. 각 RCU는 강력한 일관성이 있는 읽기 1회를 제공하는데 항목을 쓰고 다시 읽는 경우 최신 값을 얻을 수 있다는 뜻이다.
강력한 일관성 요구 사항을 완화하고 싶은 경우 RCU 하나로 초당 2회의 최종 일관성 읽기를 얻을 수 있다.
WCU, 즉 쓰기 용량 단위란 최대 1KB 크기 항목의 초당 쓰기 1회를 말한다.
예시문항 3
읽기 전용 복제본을 지원하는 Amazon Relational Database Services(Amazon RDS) 데이터베이스 엔진은 무엇입니까?
A. Microsoft SQL Server 및 Oracle
B. MySQL, MariaDB, PostgreSQL, Aurora
C. Aurora, Microsoft SQL Server, Oracle
D. MySQL 및 PostgreSQL
해설
꼭 기억할 점은 Microsoft SQL Server와 Oracle을 제외한 모든 데이터베이스 엔진이 읽기 전용 복제본을 지원한다는 것이다.
따라서 A,C,D를 제거할 수 있다.
정답은 B이다.
예시문항 4
비관계형 데이터베이스에 가장 적합한 AWS 데이터베이스 서비스는 무엇입니까?
A. Amazon Redshift
B. Amazon Relational Database Service(Amazon RDS)
C. Amazon Glacier
D. Amazon DynamoDB
해설
Redshift는 관계형이므로 A를 제거할 수 있다. 같은 이유로 B도 제거할 수 있다.
Glacier는 데이터베이스 서비스가 아니기 때문에 제거할 수 있다.
정답은 D이다.
3. 캐싱
애플리케이션 성능 향상 방법을 생각할 때 살펴봐야 할 중요한 것 중 하나가 캐싱이다.
캐싱은 핵심 로직이나 알고리즘을 재설계하거나 재작성하지 않고도 애플리케이션의 성능을 향상시킬 수 있다.
많은 경우에 캐싱은 성능 개선의 효과를 바로 볼 수 있는 간편한 방법이다.
다양한 수준에서 애플리케이션의 데이터를 캐싱할 수 있다.
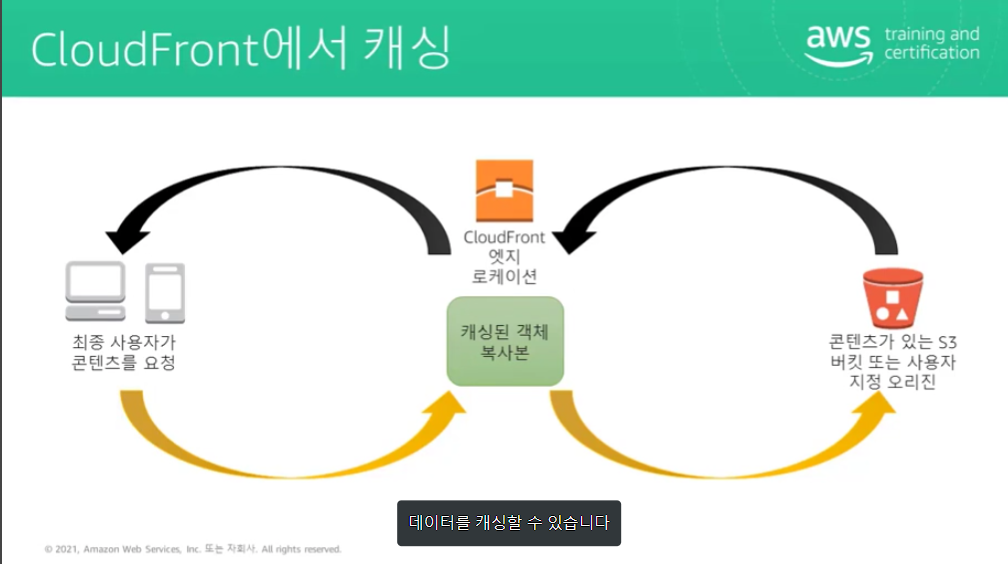
CloudFront 같은 CDN을 사용하여 캐싱이 가능하다.
Clound Front는 사용자와 가까이 있는 정적 콘텐츠를 캐싱한다. 그러면 콘텐츠를 요청할 때 요청이 데이터가 저장된 리전의 S3를 다시 거칠 필요 없이 사용자와 가까운 CloudFront 엣지 로케이션에서 콘텐츠를 제공할 수 있다.
CloudFront는 CDN, 즉 콘텐츠 전송 네트워크이다. CloudFront는 웹 애플리케이션의 성능 향상에 도움이 된다.
0
사용자가 데이터를 요청하면 최적의 엣지 로케이션으로 요청이 라우팅된다. 엣지 로케이션에 데이터가 없다면 오리진에서 데이터를 가져온다.
이제 데이터는 엣지 로케이션에 캐싱되고 사용자에게 전송된다. 다음에 누군가가 이 데이터를 요청하면 이미 캐시에 데이터가 있기 때문에 오리진까지 왕복할 필요가 없다.
애플리케이션 수준과 데이터베이스 수준에서도 캐싱을 적용할 수 있다.
ElasticCache를 사용하여 캐싱하면 데이터베이스 백엔드에서 반복해 데이터를 가져올 필요가 없다. 데이터베이스 백엔드에 캐시를 사용하면 데이터베이스의 부하도 어느 정도 덜 수 있다. 게다가 쿼리의 왕복 시간도 개선할 수 있다. 많은 쿼리가 데이터베이스 대신 캐시에 적중하기 때문이다.
ElasticCache는 두 가지 캐시를 제공하는 서비스이다.
Memcached
- 멀티스레딩
- 유지 관리 용이
- Auto Discovery를 통한 간편한 수평 조정
Redis
- 데이터 구조 지원
- 지속성
- 최소 단위 작업
- Pub/Sub 메시징
- 읽기 전용 복제본/페일오버
- 클러스터 모드/분할된 클러스터
ElasticCache를 사용하여 관리형 Memcached를 사용하거나 관리형 Redis를 사용할 수 있다.
두 가지의 차이점은 무엇일까?
Memcached는 더 간편히 설정할 수 있다.
Redis는 더 정교하고 여러 데이터 형식을 지원한다. 단순한 키 값 스토어 이상이다.
사용 사례에 따라 둘 중 하나를 사용하면 된다. ElasticCache가 알아서 설정한다.
그러면 Memcached와 Redis가 제공하는 표준 API를 사용하여 상호 작용할 수 있다.
예시문항 5
다음 중 캐시에 저장하기 좋은 객체는 무엇입니까? (3개 선택)
A. 세션 상태
B. 장바구니
C. 제품 카탈로그
D. 은행 계좌 잔액
해설
장바구니가 데이터베이스 뿐만 아니라 캐시에도 있어야 하는 시나리오가 있을 수 있다.
은행 계좌 잔액은 가장 최신 데이터를 가져야하므로 캐시가 아닌 데이터베이스에 저장하는 것이 좋다.
정답은 A, B, C 이다.
예시문항 6
다음 중 Amazon ElastiCache가 지원하는 캐시 엔진은 무엇입니까? (2개 선택)
A. MySQL
B. Memcached
C. Redis
D. Couchbase
해설
정답은 B, C 이다.
4. Amazon CloudFront
CloudFront는 인터넷을 통한 콘텐츠 전송 속도를 높이는 데 유용하다.
Amazon CloudFront
- 사용 사례 및 이점
- 콘텐츠 - 정적 및 동적
- 오리진 - S3, EC2, ELB, HTTP 서버
- 프라이빗 콘텐츠 보호
- 보안 개선
- AWS Shield Standard 및 Advance
- AWS WAF
Amazon CloudFront는 정적 콘텐츠뿐 아니라 동적 콘텐츠에도 사용할 수 있다. 예를 들어 CloudFront를 사용하면 TTL(Time to Live)이 0인 콘텐츠를 웹 서버에서 제공할 수 있다.
동적 콘텐츠에 CloudFront를 사용하면 어떤 이점이 있을까? 캐싱의 이점을 가지지는 못하지만 요청과 응답이 퍼블릭 인터넷 대신 AWS 백본을 통해 이동한다는 이점이 있다.
정적 콘텐츠의 경우 오리진을 S3로 설정할 수 있고 동적 콘텐츠의 오리진은 EC2 인스턴스, Elastic Load Balancer 또는 HTTP 서버가 될 수 있다.
CloudFront는 SSL을 지원하므로 프라이빗 콘텐츠가 안전하다. 또 서비스 거부 공격으로부터 보호하는 AWS Shield와 통합되어 있다.
웹 애플리케이션 방화벽인 WAF와도 통합되어 있다.
WAF를 사용하면 요청의 내용을 보고 요청을 필터링할 수 있다.
수신되는 트래픽 양에 관계없이 애플리케이션 성능을 향상시키려면 조정이 가능해야 한다.
트래픽 스파이크에 대응하여 확장하면 성능이 향상된다. 이와 동시에 트래픽이 줄어들 때 축소하면 비용을 억제하는 데 도움이 된다.
수직적 조정과 수평적 조정 비교
- 수직적 조정(스케일 업 및 스케일 다운)
- 인스턴스의 사양 변경(CPU, 메모리 추가)
- 수평적 조정(스케일 인 및 스케일 아웃)
- 인스턴스의 수 변경(필요에 따라 인스턴스를 추가 및 제거)
애플리케이션에서 고려해야 할 두 가지 종류의 조정이 있다.
수직적 조정은 작은 인스턴스를 큰 인스턴스로 교체하는 것이다. 이를 스케일 업 및 스케일 다운이라고도 한다.
수평적 조정은 인스턴스의 수를 늘리거나 줄이는 것이다. 이를 스케일 인 및 스케일 아웃이라고 한다.
이 용어를 기억해 두는 것이 좋다. 애플리케이션을 수직 조정할지 수평 조정할지 묻는 문제가 시험에 나올 수 있기 때문이다.
Auto Scaling
- 인스턴스 시작 또는 종료
- 새 인스턴스를 로드 밸런서에 자동으로 등록
- 여러 가용 영역에 걸쳐 시작할 수 있음
필요할 때는 인스턴스를 추가하고 필요하지 않을 때는 인스턴스를 제거하는 서비스 또는 티어 수평 조정을 하는 가장 쉬운 방법은 AWS Auto Scaling을 사용하는 것이다.
Auto Scaling은 AZ에서 인스턴스를 시작하고 종료할 수 있다. 자동으로 로드 밸런서에 인스턴스를 등록하고 인스턴스가 종료되기 전에 등록을 해제할 수도 있다.
Auto Scaling의 작동 원리는 이렇다.
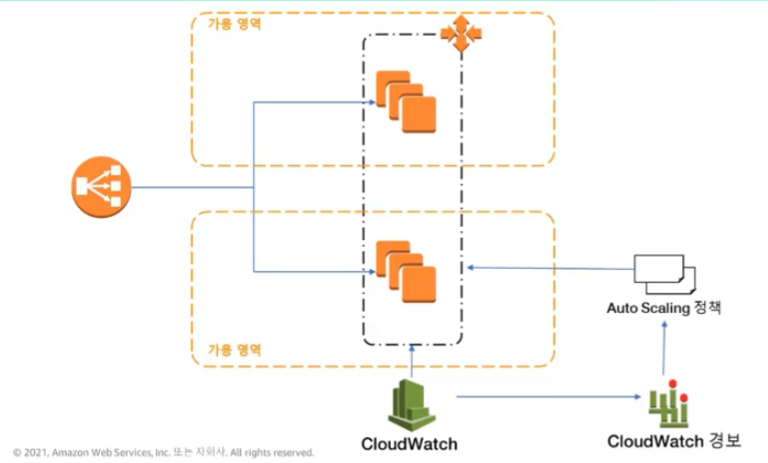
왼쪽의 원이 로드 밸런서이다.
AWS의 모니터링 서비스인 CloudWatch를 사용하여 인스턴스를 모니터링한다. 예를 들어 인스턴스에서의 CPU 사용률을 모니터링 할 수 있다.
CloudWatch에는 지표가 임계값을 초과하면 경보를 시작하는 멋진 기능이 있다. CPU 사용률이 적당한 수준, 예를 들어 80%를 넘으면 알림을 생성하도록 경보를 설정할 수 있다.
Auto Scaling은 이 CloudWatch 경보를 가로챈다. 여기서 Auto Scaling 정책을 사용하여 어떤 작업을 수행할지 지정한다. 이 정책은 시작할 인스턴스 수와 인스턴스 유형을 결정한다.
예시문항 7
EC2 인스턴스에서 Auto Scaling을 사용하려면 어떤 서비스를 연동해야 합니까?
A. Auto Scaling 및 Elastic Load Balancer
B. Auto Scaling 및 Cloud Watch
C. Auto Scaling 및 Elastic Load Balancer, Cloud Watch
D. Elastic Load Balancer 및 CloudWatch
E. Auto Scaling
해설
정답은 C 이다.
예시문항 8
Auto Scaling은 완벽하게 구성된 인스턴스를 자동으로 시작하기 위해 어떤 템플릿을 사용합니까?
A. AMI ID
B. 인스턴스 유형
C. 키 페어
D. 시작 구성
E. 사용자 데이터
해설
Auto Scaling에는 사용자 개입 없이 새 인스턴스를 자동으로 시작할 방법이 필요한데 이를 위해 일종의 인스턴스 레시피가 필요하다.
이 레시피에는 AMI ID가 필요하지만 AMI ID로는 충분하지 않다. 인스턴스 유형도 필요하고 키 페어와 사용자 데이터도 필요할 수 있다.
사용자 데이터는 인스턴스가 처음으로 시작될 때 실행되는 스크립트이다.
답을 하나만 골라야 하기 때문에 정답은 시작 구성이어야 한다.
실제로 시작 구성에는 새 인스턴스를 시작하는 데 필요한 모든 정보가 포함되어 있다. 여기 나열된 모든 항목이 있다.
정답은 D 이다.
5. Auto Scaling
Auto Scaling 구성 요소
- Auto Scaling 시작 구성
- EC2 인스턴스 크기 및 AMI 이름 지정
- Auto Scaling 그룹
- 시작 구성을 참조
- Auto Scaling 그룹의 최소 및 최대의 인스턴스 수를 지정하고 원하는 크기를 지정
- ELB 참조 가능
- 상태 확인 유형
- Auto Scaling 정책
- 스케일 인 또는 스케일 아웃 규모 지정
- Auto Scaling 그룹에 하나 이상 연결 가능
Auto Scaling을 설정하는 데 필요한 사항이다.
시작 구성은 EC2 인스턴스 크기와 AMI 이름, 인스턴스 시작을 위한 기타 정보를 지정한다.
Auto Scaling 그룹은 시작 구성을 가리킨다. 최소 인스턴스 수와 최대 인스턴스 수를 지정한다. 원하는 인스턴스 수도 지정한다. 원하는 인스턴스가 현재 설정이다.
이것이 로드 밸런서를 가리키도록 하고 인스턴스 도움말을 확인하는 방법을 지정한다.
마지막으로 Auto Scaling 정책은 스케일 인과 스케일 아웃의 규모를 지정한다.
여러 Auto Scaling 정책을 Auto Scaling 그룹에 연결할 수 있다.
Auto Scaling은 CloudWatch를 사용하여 스케일 인할 시기와 스케일 아웃할 시기를 결정한다.
CloudWatch 지표
- CloudWatch가 모니터링할 수 있는 대상 확인
- CPU
- 네트워크
- 대기열 크기
- CloudWatch Logs 이해
- 기본 지표와 사용자 지정 지표의 차이점 이해
CloudWatch는 CPU 사용률, 네트워크 지표, 대기열 크기 등의 지표를 모니터링할 수 있다.
CloudWatch에는 EC2 인스턴스, Lambda 또는 CloudTrail에서 로그를 수집하는 CloudWatch Logs라는 기능이 있다. CloudWatch Logs에 로그를 지정할 수 있다.
패턴을 사용하여 지표를 추출하면 로그를 지표로 변환할 수도 있다.
CloudWatch는 여러 AWS 서비스 및 리소스에 대한 기본 지표를 제공한다.
애플리케이션에서 사용자 지정 지표를 정의할 수도 있다.
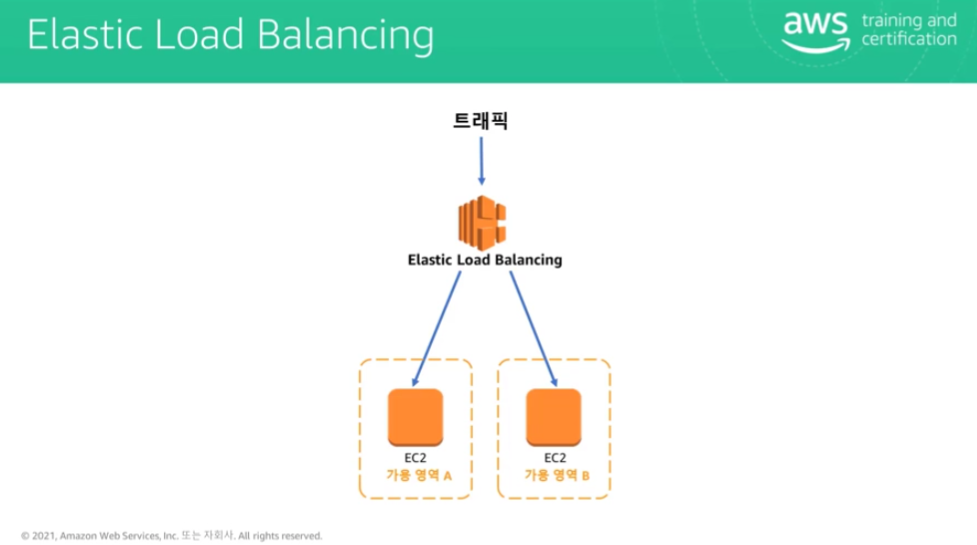
로드 밸런서는 여러 인스턴스에 트래픽을 분산한다.
이것이 Auto Scaling 설정에서 중요한 세 가지 요소이다.
로드 밸런서를 설정한 다음 Auto Scaling 그룹을 설정하고 CloudWatch 경보를 수신하도록 Auto Scaling을 구성한다.
그런 다음 두 인스턴스를 Auto Scaling 그룹에 추가한다.
여기서 로드 밸런서가 중요하다.
Auto Scaling이 인스턴스를 추가할 때마다 로드 밸런서에도 등록해야 하기 때문이다.
학습을 위한 자료 및 위치
- 학습 안내서 5장
- Auto Scaling Qwiklab
- ELB FAQ
- CloudWatch FAQ
- Auto Scaling 그룹 FAQ
예시문항 9
한 라디오 방송국에서 개최하는 콘테스트는 매일 정오에 우승자를 발표합니다. 이로 인해 8개의 EC2 인스턴스가 있어야 처리 가능한 일시적인 트래픽 스파이크가 발생합니다. 평소 이 웹사이트에는 2개의 EC2 인스턴스가 필요합니다.
다음 중 이러한 요구 사항을 충족하기에 가장 비용 효과적인 방법은 무엇입니까?
A. 최소 용량이 2개인 Auto Scaling 그룹을 생성하고 CPU 사용률에 따라 확장
B. 항상 최소 용량이 8개로 유지되는 Auto Scaling 그룹 생성
C. 최소 용량은 2개이지만 오전 11시 40분에 확장이 예정된 Auto Scaling 그룹 생성
D. 최소 용량은 2개이지만 메모리 활용도에 따라 확장이 가능한 Auto Scaling 그룹 생성
해설
B는 필요한 인스턴스 수에 비해 과도한 프로비저닝이므로 제거할 수 있다. 대부분의 경우 2개의 인스턴스만 필요하다.
D도 제거할 수 있다. CloudWatch는 인스턴스의 프로세스 공간에 엑세스하지 않으므로 메모리 사용률을 추적할 수 없기 때문이다.
A도 제거할 수 있는데 Auto Scaling이 인스턴스를 시작할 때면 너무 늦기 때문이다. 매일 정오에 발생하는 것을 알고 있는 이 트래픽 스파이크에 대비해야 한다.
따라서 C가 정답이다. 인스턴스가 20분 안에 시작된다는 가정 하에 오전 11시 40분에 확장하도록 예약할 수 있다.
인스턴스가 30분 후에 시작되면 어떻게 해야 할까? 그렇다면 오전 11시 30분에 확장하도록 예약해야 한다.
하지만 이게 정답이라고 할 수는 없다. 주어진 답안 중에 가장 타당한 답을 택하면 된다.
예시문항 10
Auto Scaling 그룹의 EC2 인스턴스에서 애플리케이션이 실행되고 있습니다. 이 애플리케이션은 9개의 EC2 인스턴스에서 실행되는 것이 최적이며, 짧은 시간 동안은 6개 이상의 인스턴스가 있어야 최소한의 성능을 유지할 수 있습니다.
다음 중 이러한 요구 사항을 충족시키는 가장 비용 효과적인 Auto Scaling 그룹 구성은 무엇입니까?
A. 2개 가용 영역의 인스턴스 9개가 바람직
B. 3개 가용 영역의 인스턴스 9개가 바람직
C. 2개 가용 영역의 인스턴스 12개가 바람직
D. 1개 가용 영역의 인스턴스 9개가 바람직
해설
AZ 하나를 사용할 수 없게 되면 인스턴스가 6개 미만이 되므로 A를 제거할 수 있다.
하나의 AZ에 모든 인스턴스를 넣으면 가용성이 높지 않기 때문에 D도 제거할 수 있다.
B와 C 중에서 B가 더 비용 효과적이다. C도 효과는 있지만 컴퓨팅 리소스가 너무 많이 들기 때문에 제거할 수 있다.
그러면 정답은 B가 된다.
AZ 하나를 사용할 수 없게 되어도 허용 가능한 수준의 성능을 제공하기에 충분한 인스턴스가 있는 것을 알 수 있다.
예시문항 11
다음 중 AWS의 Auto Scaling 서비스의 특징은 무엇입니까? (3개 선택)
A. 트래픽을 정상 작동 인스턴스에 전송합니다.
B. Amazon EC2 인스턴스를 추가 또는 종료하여 변화하는 상황에 대응합니다.
C. 지표를 수집 및 추적하고 경보를 설정합니다.
D. 푸시 알림을 제공합니다.
E. 지정된 Amazon Machine Image(AMI)에서 인스턴스를 시작합니다.
F. 실행 Amazon EC2 인스턴스의 최소 수를 적용합니다.
해설
A는 Elastic Load Balancer 작업이므로 제거할 수 있다.
B는 정답 중 하나인 것 같다.
지표 수집과 추적은 CloudWatch가 하는 일이므로 C도 제거할 수 있다.
D는 Amazon Simple Notification Service, 즉 SNS에 대한 설명이므로 제거할 수 있다.
그러면 답 3개가 남는다.
Auto Scaling은 EC2 인스턴스를 추가 또는 종료해 변화하는 조건에 대응하고 지정된 AMI에서 인스턴스를 시작하고 최소 실행 Amazon EC2 인스턴스 수를 적용한다.
예시문항 12
애플리케이션의 웹 티어가 ELB Classic Load Balancer 뒤에 있는 2개의 가용 영역에 분산된 6개의 EC2 인스턴스에서 실행되고 있습니다. 데이터 티어는 EC2 인스턴스에서 실행 중인 MySQL 데이터베이스입니다.
애플리케이션의 가용성을 높이기 위해서는 어떤 변화가 필요합니까? (2개 선택)
A. Classic Load Balancer에서 교차 영역 로드 밸런싱을 활성화합니다.
B. Auto Scaling 그룹에서 웹 티어 EC2 인스턴스를 시작합니다.
C. 웹 티어 EC2 인스턴스의 크기를 늘립니다.
D. MySQL 데이터베이스를 다중 AZ RDS MySQL 데이터베이스 인스턴스로 마이그레이션합니다.
E. 애플리케이션의 AWS 계정에서 CloudTrail을 활성화합니다.
해설
A는 효과가 최소이기 때문에 제거할 수 있다.
C는 효과가 없기 때문에 제거할 수 있다. 인스턴스 크기를 늘려도 가용성에는 영향이 없다.
E도 제거할 수 있다. API 호출을 모니터링하는 데는 도움이 되지만 가용성에는 영향이 없다.
그러면 2개의 답이 남는다.
B, Auto Scaling 그룹에서 웹 티어 EC2 인스턴스를 시작하는 것과 D. MySQL 데이터베이스를 다중 AZ RDS MySQL 데이터베이스 인스턴스로 마이그레이션하는 것이다.
이 두 가지 모두 가용성을 높인다.
6. 운영 우수성
운영 우수성의 기본 개념은 변화하는 상황에 적응하는 자동화된 시스템을 갖추는 것이다.
운영 우수성
- 시스템을 실행 및 모니터링하여 비즈니스 가치를 제공하고 지속적으로 지원 프로세스 및 절차를 개선하는 능력이다.
- 준비
- 운영
- 진화
관건은 시스템 시작 전에 준비하는 것이다. 자동화된 방식으로 운영한 다음, 시간이 지남에 따라 시스템을 학습하고 발전시켜 지속적으로 개선하는 것이다.
몇 가지 운영 우수성의 모범 사례가 나와 있다.
운영 우수성: 설계 원칙
- 코드로 운영 수행
- 문서에 주석 추가
- 빈번하고 작은 규모로 되돌릴 수 있는 변화 수행
- 운영 절차를 빈번하게 재정의
- 장애를 예측
- 모든 운영 실패에서 학습
코드를 사용하여 운용하다. 인프라 운영은 자동화하는 것이 좋다.
설명서에 주석을 추가한다. AWS에서는 설명서가 자동화 스크립트로 구성되는 경우가 많다. 설명서가 배포된 리소스를 실시간으로 나타낼 수 있도록 설명서에 주석을 추가하는 것이 좋다.
소규모의 취소 가능한 변경을 빈번히 수행한다. 시스템을 모니터링할 방법이 필요하다. 변경 후에는 시스템의 동작을 관찰한다. 변경으로 눈에 띄는 개선이 없다면 변경을 되돌려야 한다.
운영 및 절차를 수시로 개선한다. 운영을 지속적으로 개선해야 한다.
실패를 예상한다. 게임 데이를 연습하고 실패를 예상하여 대비한다.
모든 운영 실패로부터 교훈을 얻어야 한다. 실패가 발생할 때 시스템을 발전시키고 강화해야 같은 장애가 재발하지 않는다.
다음은 운영 우수성을 지원하는 서비스이다.
운영 우수성을 지원하는 AWS 서비스
- AWS Config
- AWS CloudFormation
- AWS Trusted Advisor
- AWS Inspector
- VPC Flow Logs
- AWS CloudTrail
Config는 EBS 볼륨 및 EC2 인스턴스 같은 리소스를 추적한다. Config는 새 리소스가 구성 규칙을 준수하는지 확인한다.
CloudFormation은 JSON 및 YAML 템플릿을 인프라와 리소스로 변환한다.
CloudTrail은 API 호출을 로깅한다.
VPC Flow Logs는 네트워크 트래픽을 로깅한다.
Inspector는 EC2의 보안 취약점을 검사한다.
Trudsted Advisor는 계정에서 보안, 안정성, 성능, 비용, 서비스 한도에 관한 모범 사례를 검사한다.
운영 우수성을 위한 또 다른 중요한 서비스는 CloudWatch이다. CloudWatch는 지표를 추적하고 지표가 초과되면 경보를 시작한다.
CloudWatch Logs는 EC2 인스턴스 CloudTrail, Lambda의 로그 파일을 저장한다. 로그 라인에서 패턴을 추출하여 로그 파일을 지표로 변환할 수도 있다.
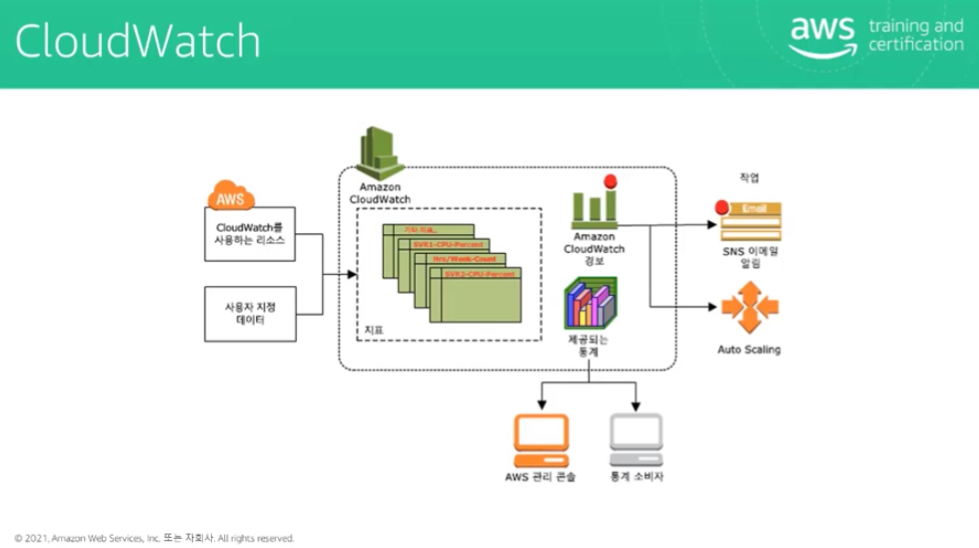
예시문항 13
RDS 인스턴스의 CPU 사용률을 모니터링하기 위해서 5분 기간 3회에 걸쳐 임계값 70%로 CloudWatch 경보를 설정합니다. CPU 사용률이 10분 동안 80%까지 올라가면 몇 개의 경보를 받게 됩니까?
A. 0개
B. 1개
C. 2개
D. 3개
해설
지표가 임계값을 초과한 시간이 15분을 넘지 않으므로 경보는 발생하지 않는다.
정답은 A 다.
예시문항 14
Amazon EC2 인스턴스에서 실행 중인 웹 애플리케이션은 사용자의 책임입니다. 따라서 사용자는 애플리케이션에 나타나는 404 오류의 수를 추적하고 싶을 것입니다.
다음 옵션 중 어떤 것을 사용할 수 있습니까?
A. VPC Flow Logs를 사용합니다.
B. CloudWatch 지표를 사용합니다.
C. CloudWatch Logs를 사용하여 EC2 인스턴스에서 웹 서버 로그를 가져옵니다.
D. AWS의 웹 애플리케이션에서는 절대 404 오류가 발생하지 않습니다.
해설
A는 제거해도 된다. VPC Flow Logs는 계층 3 및 4의 IP 수준 로그를 캡처하며 계층 7 HTTP 404 오류는 캡처하지 않는다.
B도 제거할 수 있다. CloudWatch 지표는 404 오류를 캡처하지 않는다.
AWS의 웹 애플리케이션에도 404 오류가 발생할 수 있으므로 D도 제거할 수 있다.
CloudWatch Logs를 사용하여 EC2 인스턴스에서 웹 서버 로그를 가져올 수 있다.
예시문항 15
S3의 특정 버킷에 엑세스해야 하는 애플리케이션을 작성했다고 합시다. 이 애플리케이션은 EC2 인스턴스에서 실행됩니다. 애플리케이션이 버킷에 안전하게 엑세스하도록 하려면 어떻게 해야 합니까?
A. EC2 인스턴스의 ‘secrets’라는 파일에 엑세스 키와 비밀 엑세스 키를 저장합니다.
B. S3의 버킷에 대한 엑세스 권한을 부여하는 정책을 사용하여 IAM 역할을 EC2 인스턴스에 연결합니다.
C. EC2 인스턴스의 ‘$HOME/.aws/credentials’에 엑세스 키와 비밀 키를 저장합니다.
D. S3 버킷 정책을 사용하여 버킷을 퍼블릭으로 설정합니다.
해설
A는 제거해도 된다. 인스턴스에 키를 저장하는 것은 좋지 않다.(안티패턴)
같은 이유로 C도 제거할 수 있다.(이것도 안티패턴)
버킷을 퍼블릭으로 설정하면 지나치게 광범위한 엑세스 권한을 주게 된다.
역할을 인스턴스에 연결한 다음 정책을 사용하여 특정 버킷에 대한 엑세스 권한을 제공하면 된다.
7. 시험에 대한 조언
각 모듈 끝에 나오는 시험에 대한 조언은 방금 다룬 영역과 관련하여 기억해야 할 중요한 사항이다.
이 영역에서는 운영 우수성을 다뤘다.
- IAM 역할은 키와 암호보다 쉽고 안전
- 시스템 전반에서 지표를 모니터링
- 적절한 경우 지표에 대한 대응 자동화
- 비정상적 상황에 대한 알림 제공